
FedGNN: Federated Graph Neural Network for Privacy-Preserving Recommendation
Published:
Summary:
Graph Neural Networks are highly popular due to their applications in drug discovery, recommendation systems and social computing. Federated Learning tries to solve the problem of machine learning while maintaining data privacy. There have been significant works on federated learning using vision and NLP domains, but this is not the case n the GNN domain. There is no unified benchmarking system and framework for the various tasks in GNNS. This work creates such a system to promote and ease research in Federated Learning using GNNs. While there have been separate works to build such frameworks, they are limited to a specific type of GNN tasks. Thus this work makes the first unified framework for GNN. The paper starts with formulating the problem of Federated Learning on GNNs. In FL, there are K clients with their data private to them. These run GNN models locally on their data and then share their weights with a central FL server which handles the aggregation of all the received weights. In the local learning parts, there are two phases. First is the message-passing phase in which the features of neighbouring nodes of a given node are used to create an L-layer GNN that calculates the new feature of the given node. This phase is common for all types of graph learning tasks. The second phase is making the prediction using a multi-layer perceptron. This stage varies a bit depending on the nature of the graph learning task. The final goal is to minimise the aggregate of the local loss functions of each of the FL clients. The most straightforward aggregation technique is to average all the values and is called FedAvg, but there are other methods, like FedOPT and FedGKT. The unified frameworks consider three different settings for the graph learning tasks and three different types of graph learning tasks. The different settings considered are:
- Graph-level FedGraphNN: Each client holds a set of graphs, and the objective is classification/regression on these graphs. An example is protein discovery, where each institute has a limited set of graphs with labels due to expensive experiments.
- Subgraph-level FedGraphNN: Each client holds a subgraph of a larger global graph, where the typical task is node classification and link prediction. An application is knowledge graph completion, where each institute might hold a subset of entity/relation data.
- Node-level FedGraphNN: Each client holds the ego-networks of one or multiple nodes, where the typical task is node classification and link prediction. An example is social networks, where each node only sees its k-hop neighbours and their connections in the large graph. The different types of graph learning tasks are:
- Graph Classification: This task categorises different graphs based on their structure and overall information. The applications are possible in a graph-level setting.
- Link Prediction: This task estimates the probability of links between any two nodes in a graph. The applications are in the subgraph-level and node-level settings.
- Node Classification: This task predicts the labels of individual nodes in graphs. The main application is in the node-level setting, but tasks also exist in the subgraph-level setting. The work collected a set of graph datasets for different learning tasks. It has also looked into a non-IID sampling of graph datasets using Latent Dirichlet Allocation(LDA). Finally, it has proposed a secure, efficient and distributed FedGNN framework and evaluated the accuracy/loss metrics and the training time.
Main Contributions:
The three main contributions of the paper are:
- Formulation of the Federated Learning problem in GNNs and different graph learning settings and tasks.
- Collection and examination of 36 datasets from 7 domains for different graph learning tasks, of which 34 are available from publicly available sources and two new datasets: hERG [40, 20], a graph dataset for classifying protein molecules responsible for cardiac toxicity and Tencent, a large bipartite graph representing the relationships between users and groups.
- Creation of an efficient, secure, distributed and system-agnostic framework with baseline implementations of different GNN models and FL algorithms for ease of new research in this field.
Specific comments:
- The novelty of the framework lies in its use of tensor-oriented RPC API for faster communication and development of the SOTA Light Secure Aggregation algorithm.
- One assumption is that they use GNNs inductively (i.e., the model is independent of the structure of the graphs it is trained on). Thus, no topological information about graphs on any client is required on the server during parameter aggregation. This might be problematic as the graph structure might be an essential feature for better learning.
- Another conjecture is the decrease in accuracy in FL learning compared to the centralised learning on large datasets because of the non-IIDness of the graphs. This seems reasonable as in FL setting, the links between components of the clients might not be considered due to privacy.
- The accuracy achieved using the framework is less than the centralised task.
- Also, specific models like GAT diverge or have significantly low performance when trained in a federated way using the framework for subgraph-level or node-level settings.
- No details on the SOTA Light Secure Aggregation have been given.
- The authors have kept in mind the ease of researching while building the framework, which is quite commendable.
Detailed Analysis of the Solution Approach:
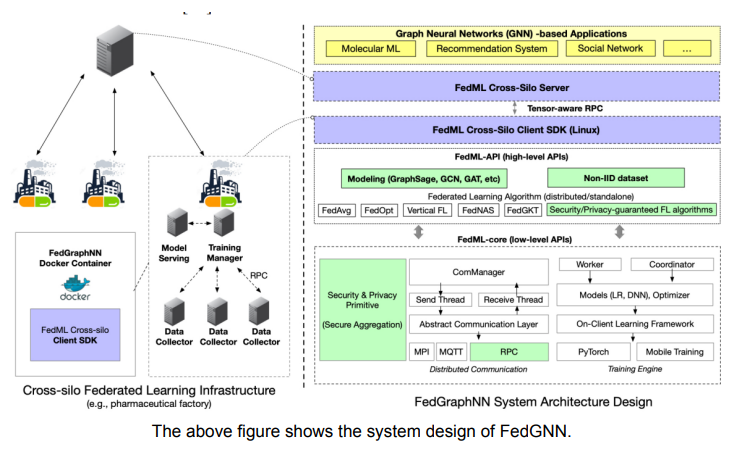
The above figure shows the system design of FedGNN. The three main highlights of the FedGNN system are:
- Enhancing realistic evaluation with efficient and deployable distributed system design: The execution is done in cross-silo settings, with edge servers being the organisation servers instead of the IoT or smartphone devices. The system design consists of three main components: FedML-core layer, FedML-API layer, and Application layer. The FedML-core layer supports tensor-oriented RPC and MPI API compared to naive gRPC for faster communication. The APIs are made abstract to simplify the message definition and passing requested by different FL algorithms in FedML-API layer. Docker containers are used for the implementation to make the framework hardware and OS independent and simplify the scalability. The researchers can make realistic evaluations in a parallel execution environment with a combination of CPU/GPUs.
- Enabling secure benchmarking with lightweight, secure aggregation: The work develops a SOTA Lightweight Segregation algorithm which performs better than existing baselines like SecAgg and SecAgg+. LightSecAgg protects the client model by generating a single random mask and allows their cancellation when aggregated at the server. Consequently, the server can only see the aggregated model and not the raw model from each client. The implementation spans across FedML-core and FedML-API.
- Facilitating algorithmic innovations with diverse datasets, GNN models, and FL algorithms: To promote future innovations, FedGNN enables flexible customisation. The GNN models and FL algorithm APIs have been modularised to support various datasets. The focus has been on reducing the code to have faster research. Detailed Analysis of Validation, experiments conducted Experiments are conducted on multiple GPU servers, each equipped with 8 NVIDIA Quadro RTX 5000 (16GB GPU memory). Results are on the ROC-AUC metric for graph classification, RMSE & MAE for graph regression, MAE, MSE, and RMSE for link prediction, and micro-F1 for node classification. The evaluation is done using GNN models like GCN, GAT and GraphSage for all three types of graph learning tasks using relevant datasets, and FedAvg is used for aggregation. The observations are that:
- For small graphs, the accuracy of FL is at par with the centralised version.
- As the graph size increases, the accuracy of FL decreases compared to the centralised learning.
- The best model in the centralised setting may not be the best in the FL task.
- Unexpected observations include the worse performance of the GAT model in graph and node classification tasks followed by better performance on the specific graphs in link-prediction tasks compared to centralised learning. For the Lightweight Secure Aggregation, the algorithm performs 12.7x better than SecAgg and 4.1x better than SecAgg+ when the dropout rate is 30% in terms of speed.
Comments on Possible Extensions/Improvements/Next Steps:
- Graphs dataset can be grown with graphs from more domains.
- The efficiency of the system can be improved further.
- Decreased FL accuracy due to non-IIDness of graphs can be further explored.
- More focus can be given on security and privacy in FL.
Conclusion:
Existing platforms like LEAF, TensorFlow Federated, PySyft, and FATE did not support graph datasets and models. So this is the first unified framework standardising FL on graphs and providing all the necessary tools. The design is such that the APIs are easy to use and hence promote ease of research in this field.