
Vision GNN: An Image is Worth Graph of Nodes
Published:
Summary:
The paper introduces the concept of applying GNNs on vision tasks. The existing architectures, such as the widely-used convolutional neural network and transformer, treat the image as a grid or sequence structure, which is not flexible to capture irregular and complex objects. The image is first divided into multiple patches. The patches are viewed as graph nodes, and edges are added between nearest neighbours. A neural network architecture has been made that takes this graph representation of images as input and does the vision task. The neural network consist of two modules: Grapher module with graph convolution for aggregating and updating graph information and FFN module with two linear layers for node feature transformation. The authors also consider isotropic and pyramid architectures while making these models and compare them against existing architectures. Their experiments have shown that these models perform better than existing models in tasks like image classification and object recognition.
Main Contributions:
- GNN model for vision tasks.
- Both istropic and pyramid type architectures.
- Thorough evaluation on standard vision tasks while comparing with existing SOTA model architectures. Specific Comments:
- The work is novel as it applies GNNs to vision tasks in a way that no work has done before.
- The inference speed of GNNs is less than the CNNs, which is a limitation and needs more research.
- The paper did not mention what metric is used finding the K nearest neighbours and the impact of the choice of metric on the performance.
- The object detection implementation details are not given.
- The experiments fixes the number of nodes to 196 and does not show how performance changes with the number of nodes.
- The concept of applying GNNs to images seemed cool to me.
Detailed Analysis of the Solution Approach:
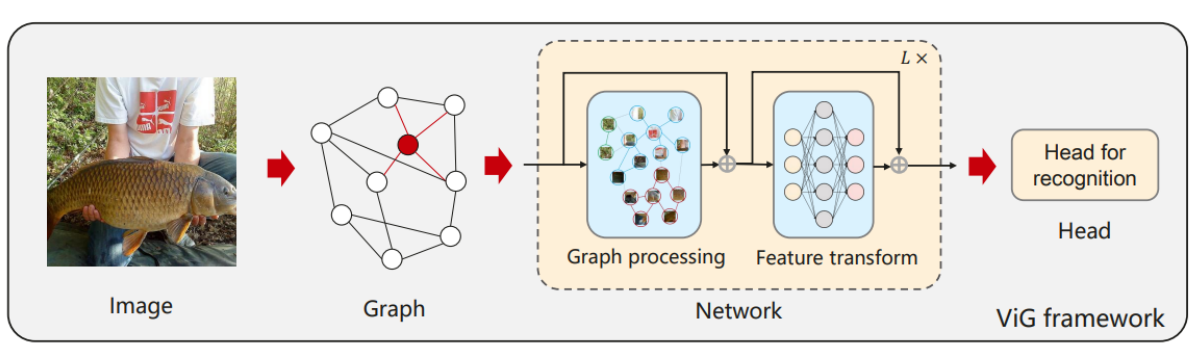 The above image shows the overview of the Vision GNN framework. The 3-channel image is divided into N patches. Each patch is represented using a feature vector of D dimensions. The N patches are considered as the nodes of the graph. K nearest neighbours are found for this node using some similarity/distance metric. This node is connected to these K neighbours using edges. The graph finally formed is used for training the GNN model. The existing works use a grid or sequence based representation for images. The graph representation is a generalised version of these. These representations might not be the best when the object is irregularly shaped. The following update equations are used to calculate the hidden representations of the model:
The above image shows the overview of the Vision GNN framework. The 3-channel image is divided into N patches. Each patch is represented using a feature vector of D dimensions. The N patches are considered as the nodes of the graph. K nearest neighbours are found for this node using some similarity/distance metric. This node is connected to these K neighbours using edges. The graph finally formed is used for training the GNN model. The existing works use a grid or sequence based representation for images. The graph representation is a generalised version of these. These representations might not be the best when the object is irregularly shaped. The following update equations are used to calculate the hidden representations of the model: 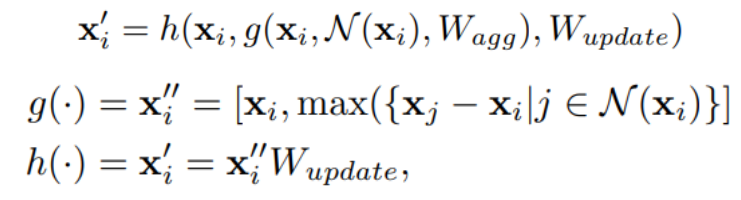
Here N(xi) represents the the neighbours of node xi. The above computation is denoted as the GraphConv(X). The aggregated features in xi’’ are divided into h heads as below: 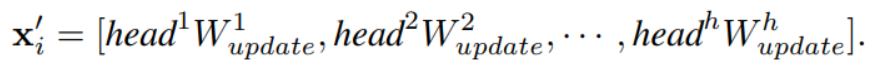
This helps in improving the feature diversity. To further increase the diversity a linear layer are added before and after GraphConv as given below: 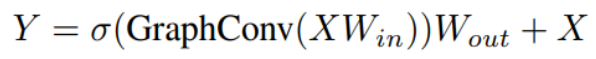
To further encourage the feature transformation capacity and relief the over-smoothing phenomenon, we utilize feed-forward network (FFN) on each node. The FFN module is a simple multi-layer perceptron with two fully-connected layers: 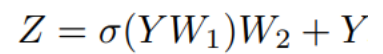
A stack of Grapher and FFN modules constitutes the ViG block, which is the basic building unit for constructing a network. Both isotropic and pyramid architectures have been made using these building units. In isotropic models the number of features stay the same throughout the main body. In contrast, in pyramid the features with gradually smaller spatial size as the layer goes deeper are used. Also the positional encoding of the nodes is added into the features vectors. Models from tiny to base with increasing number of parameters have been made.
Detailed Analysis of Validation, experiments conducted:
The experiments for image classification were done ImageNet and on COCO dataset for object detection. In image classification, comparison of isotropic models is done with DeiT, ResMLP models. The data augmentation includes RandAugment, Mixup, Cutmix, random erasing and repeated augment. In pyramid models comparison is done against ResNet, Swin T, etc. In both cases the VisGNN performs better compared to the respective sized models. An Ablation study was also conducted to see individual effect of each of their models. The results are given below: 
Thus, you can see that using all the three models gives best performance. Other experiments show that increasing the value of K for nearest neighbours improves Top-1 score by about 1.5% when going from K=3 to 9 nodes. Also using lesser number of heads is better but the drop in performance when using more heads is minimal. For object detection the comparison is done with ResNet, CycleMLP and SwinT models while using them as backbone in RCNN and RetinaNet architectures. The VisGNN shows better generalization capacity by giving better MAP in both type of architectures as compared to the other models. The authors also provide a visualisation on how the shallow layers high level features such as texture and colour are learned while in deeper layers semantic features are learned. Further works It will be interesting to see the application of GNNs on others tasks such as segmentation. Work needs to be done on improving the inference speed for GNNs as they are slower than CNNs. In general with this base work more sophisticated architectures that use GNNs for vision tasks can be explored.
